
利用青龙面板自动从Telegram频道下载文件并筛选输出IP库
前言
接上篇教程《自动从Telegram频道下载CSV文件并提取443端口IP地址》,因为在github actions自动运行,所以Telegram每次ip都会变动提醒,今天有时间把脚本修改了一下兼容青龙面板运行。
运行效果
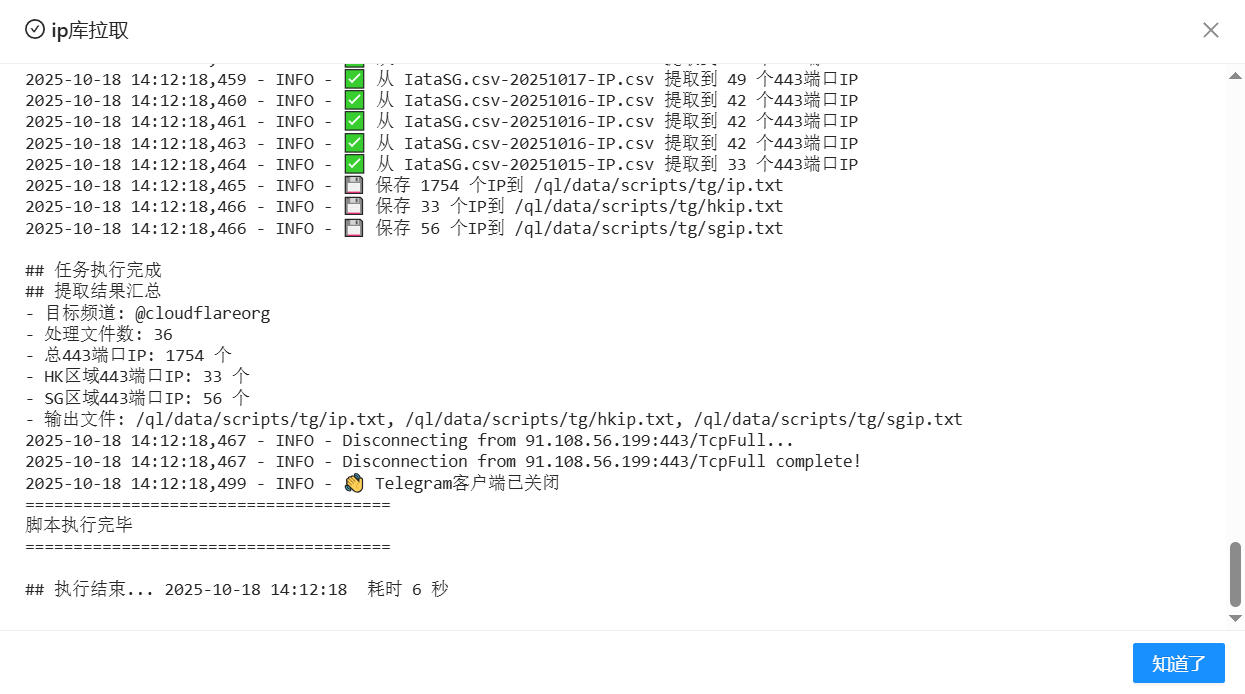
部署方法
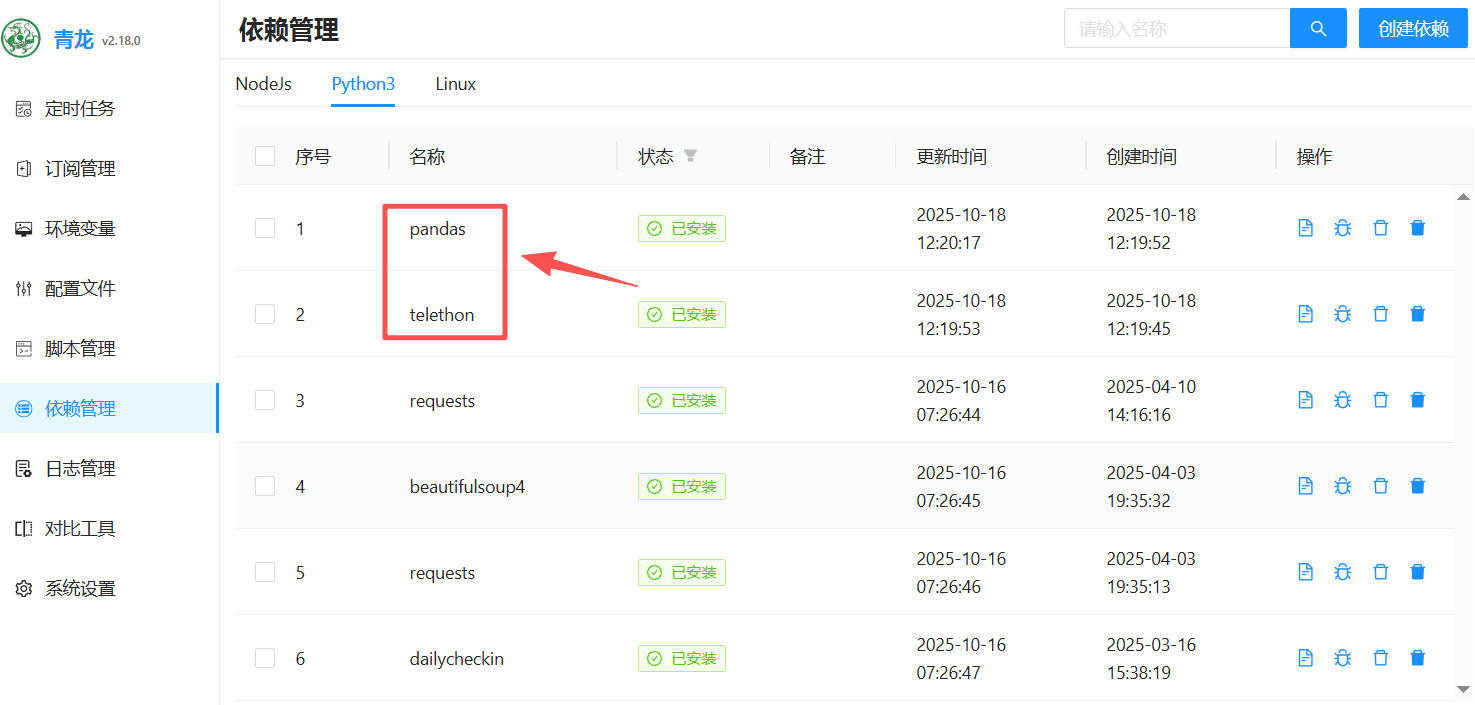
1、 进青龙面板,依赖管理里面安装pandas和telethon。如下图:
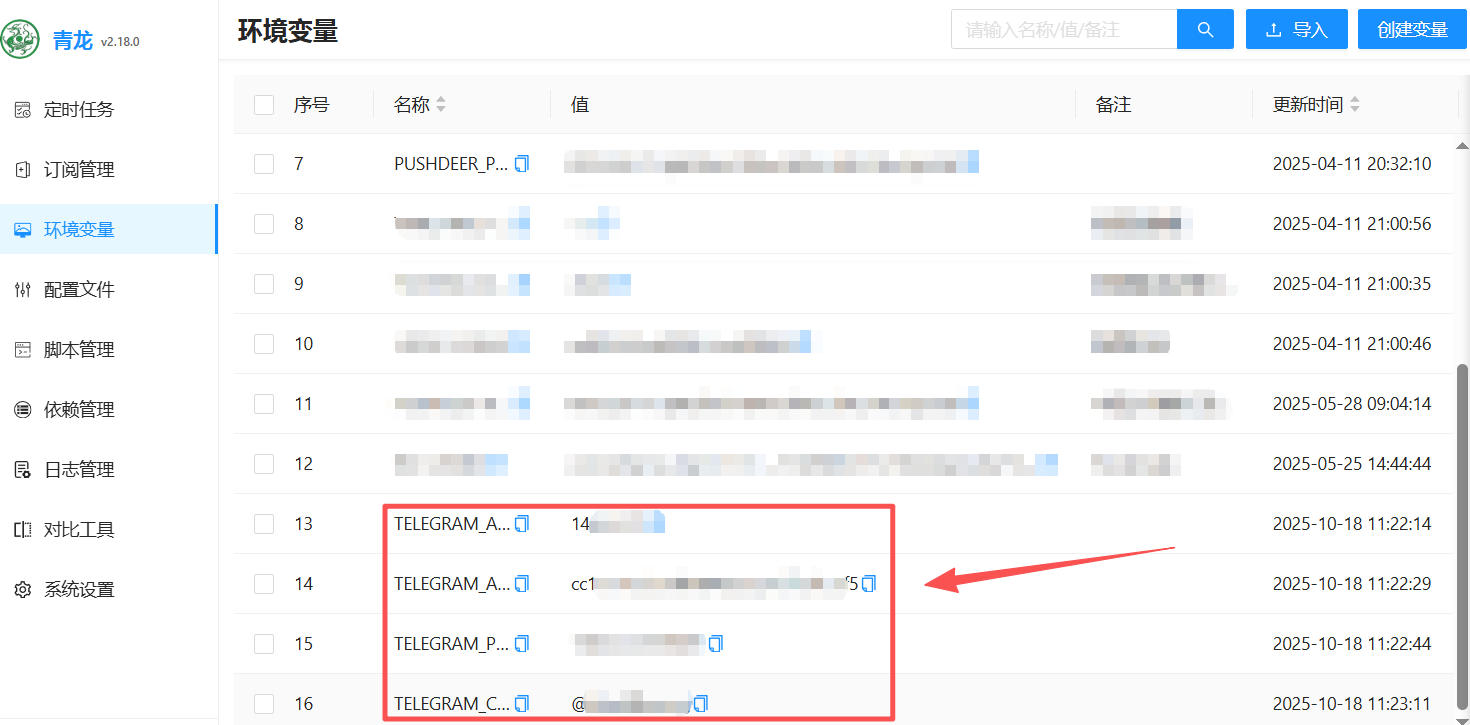
2、 进环境变量里面添加变信息信息。变量名如下:
| 变量名 | 说明 | 示例 |
|---|---|---|
TELEGRAM_API_ID |
Telegram API ID | 1234567 |
TELEGRAM_API_HASH |
Telegram API Hash | abcdef1234567890 |
TELEGRAM_PHONE |
手机号码(国际格式) | +861234567890 |
TELEGRAM_CHANNEL |
目标频道用户名 | @your_channel |
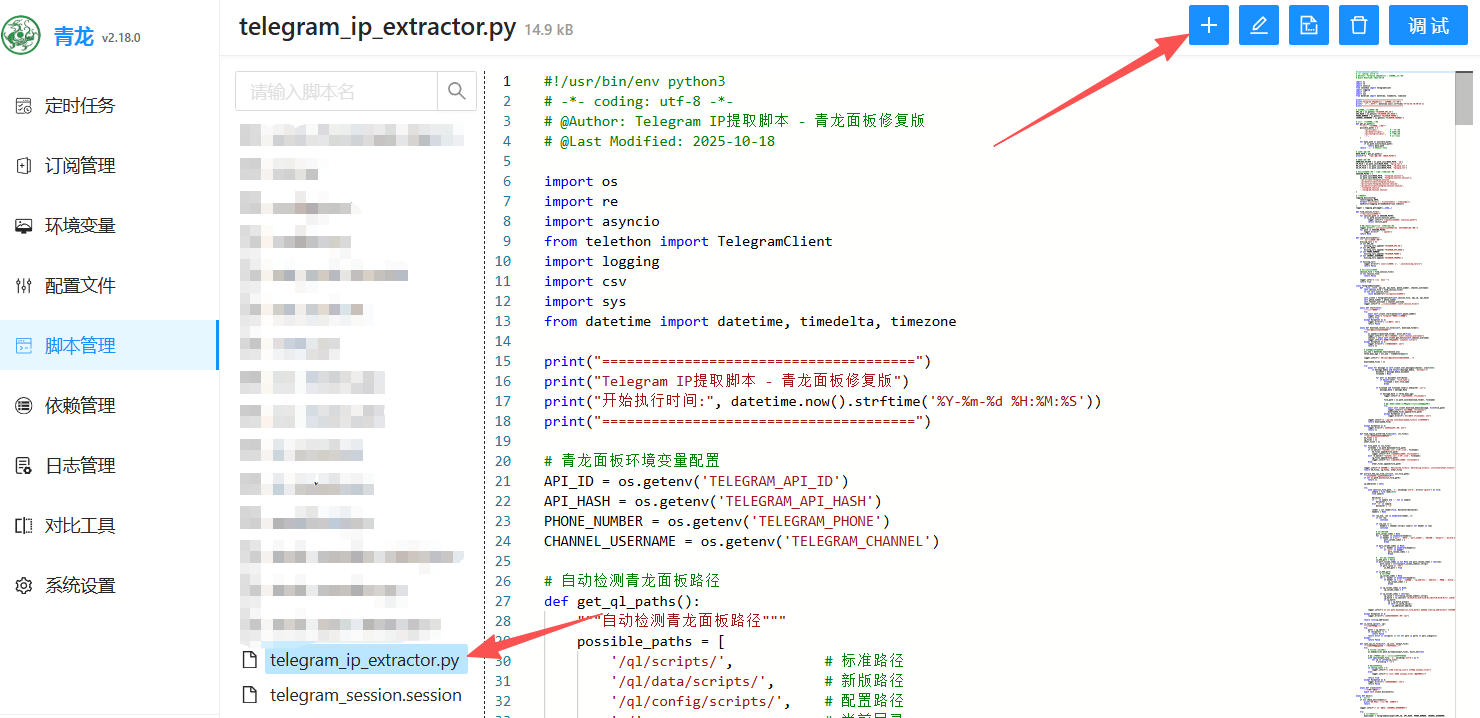
3、 进脚本管理里面新建一个名为telegram_ip_extractor.py的脚本。把最下面的脚本粘贴进去。如下图:
4、 点左侧的定时任务,创建任务。任务名称随意,命令脚本task telegram_ip_extractor.py,定时规则自己定义。
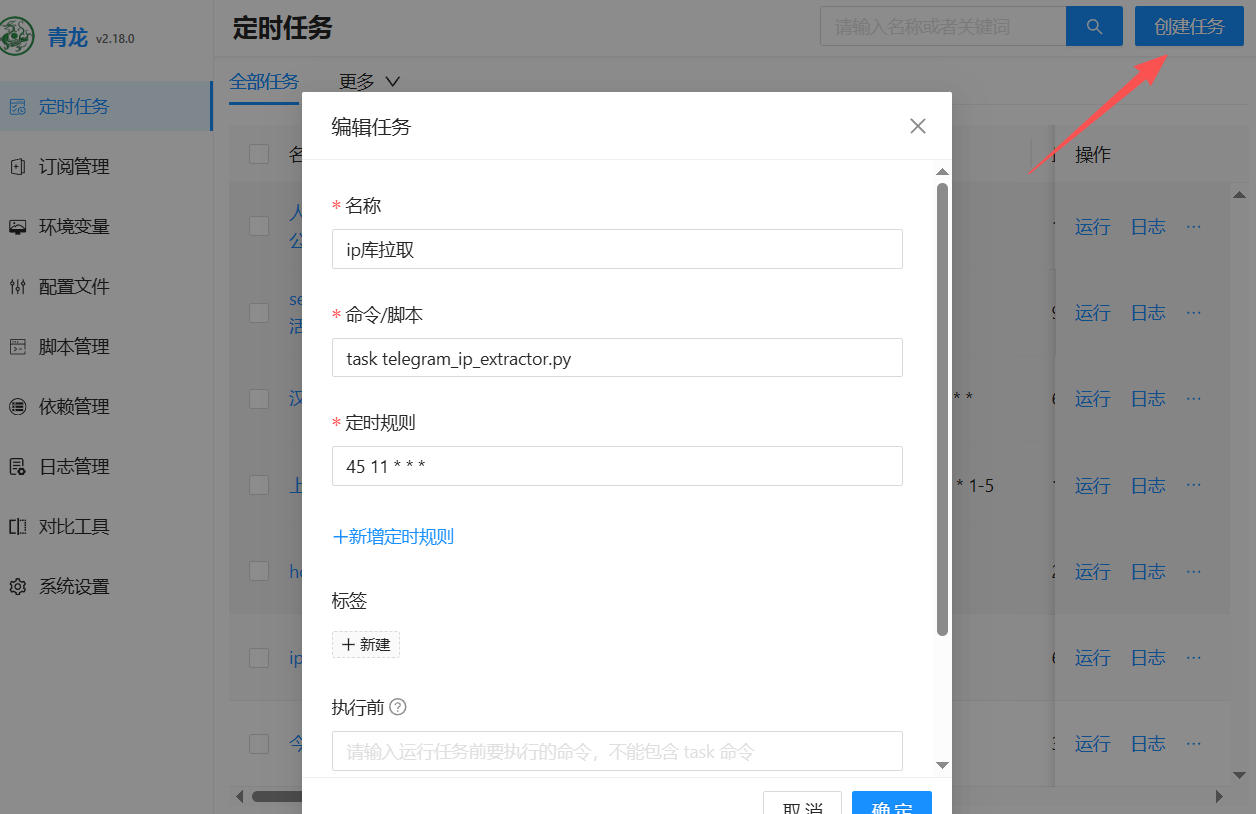
5、 手动运行一次没有报错,就可以进青龙目录下查看输出的txt文件,我这里是在群晖上搭建的Docker。所以直接进群晖查看,然后共享文件供openwrt路由优选调用。
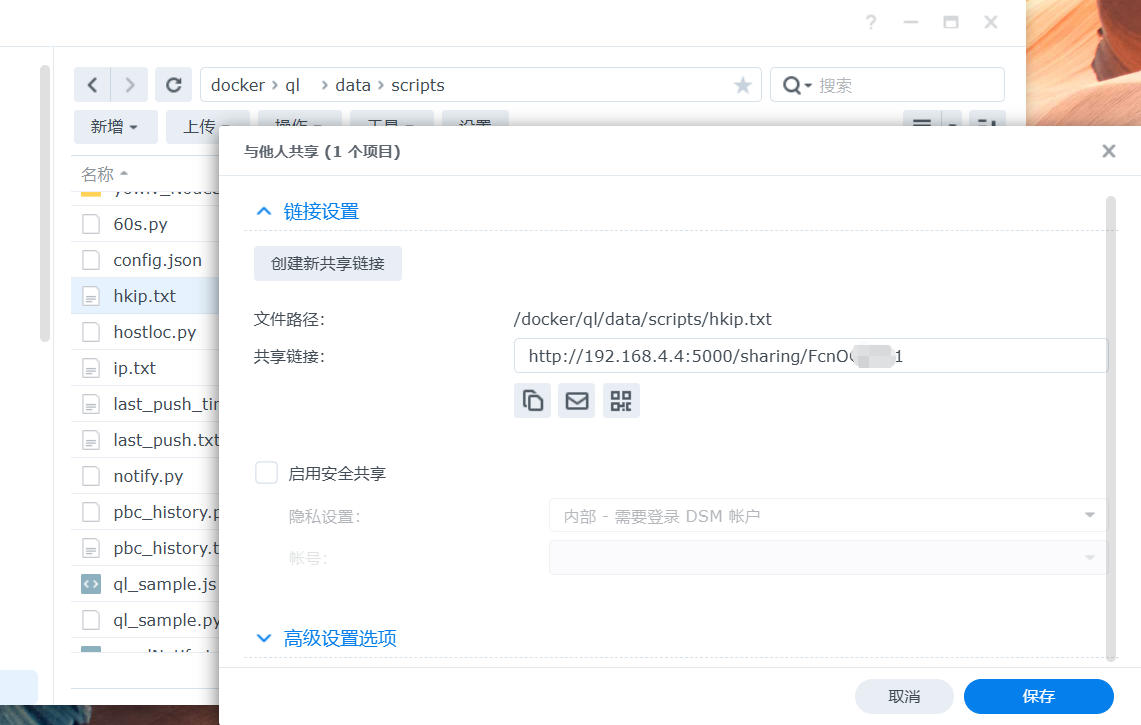
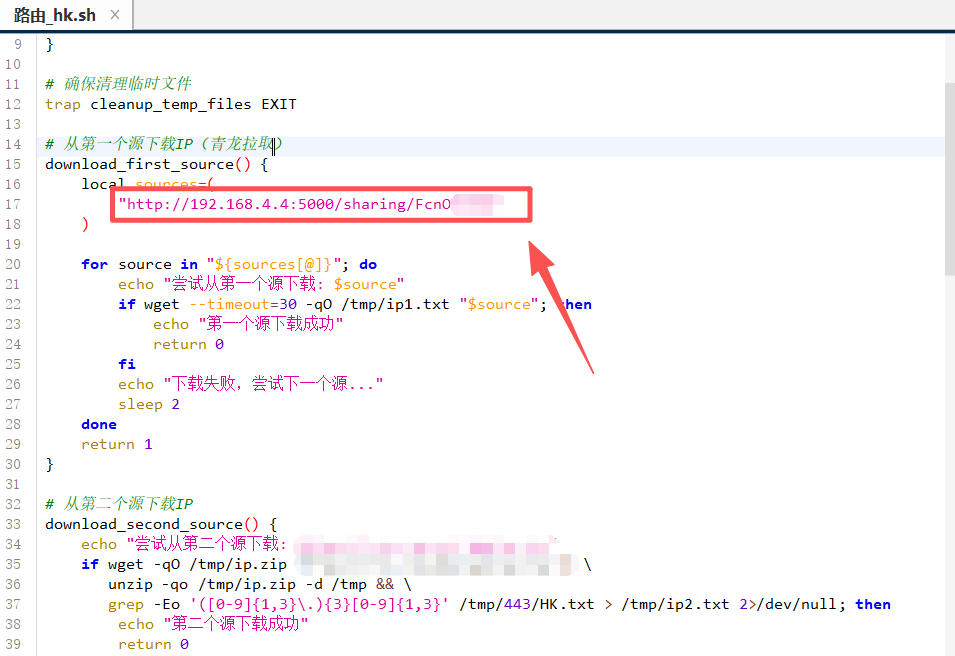
6、 最后把共享链接导入到优选脚本里面使用即可。
写在最后
第一次建议本地运行后输出telegram_session,输出文件在temp目录下。然后再导入到青龙,。
*附上本地运行获取telegram_session的脚本。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Author: Telegram 本地设置脚本
# @Date: 2024-01-01
import os
import asyncio
from telethon import TelegramClient
import tempfile
import sys
def setup_telegram():
print("=== Telegram 本地设置脚本 ===")
print("此脚本将在本地完成Telegram验证并生成session文件")
print("完成后可将session文件用于青龙面板\n")
# 获取用户输入
api_id = input("请输入 TELEGRAM_API_ID: ").strip()
api_hash = input("请输入 TELEGRAM_API_HASH: ").strip()
phone_number = input("请输入 TELEGRAM_PHONE (国际格式,如 +861234567890): ").strip()
if not all([api_id, api_hash, phone_number]):
print("错误: 所有字段都必须填写!")
return
print(f"\n配置信息:")
print(f"API ID: {api_id}")
print(f"API Hash: {api_hash}")
print(f"手机号: {phone_number}")
print("\n正在启动验证流程...")
async def authenticate():
# 使用临时目录存储session文件
temp_dir = tempfile.gettempdir()
session_file = os.path.join(temp_dir, 'telegram_session')
print(f"Session文件将保存在: {session_file}")
client = TelegramClient(session_file, int(api_id), api_hash)
try:
await client.start(phone=phone_number)
print("✅ 验证成功! Session文件已生成")
print(f"✅ Session文件位置: {session_file}")
# 测试连接
me = await client.get_me()
print(f"✅ 登录账号: {me.first_name} ({me.phone})")
print("\n🎉 设置完成! 现在您可以在青龙面板中使用以下环境变量:")
print(f"TELEGRAM_API_ID={api_id}")
print(f"TELEGRAM_API_HASH={api_hash}")
print(f"TELEGRAM_PHONE={phone_number}")
print("\n💡 提示: Session文件会自动用于后续登录,无需再次验证")
except Exception as e:
print(f"❌ 验证失败: {e}")
finally:
await client.disconnect()
# 运行异步函数
asyncio.run(authenticate())
if __name__ == "__main__":
setup_telegram()
最后附上青龙脚本
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Author: Telegram IP提取脚本 - 青龙面板修复版
# @Last Modified: 2025-10-18
import os
import re
import asyncio
from telethon import TelegramClient
import logging
import csv
import sys
from datetime import datetime, timedelta, timezone
print("======================================")
print("Telegram IP提取脚本 - 青龙面板修复版")
print("开始执行时间:", datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
print("======================================")
# 青龙面板环境变量配置
API_ID = os.getenv('TELEGRAM_API_ID')
API_HASH = os.getenv('TELEGRAM_API_HASH')
PHONE_NUMBER = os.getenv('TELEGRAM_PHONE')
CHANNEL_USERNAME = os.getenv('TELEGRAM_CHANNEL')
# 自动检测青龙面板路径
def get_ql_paths():
"""自动检测青龙面板路径"""
possible_paths = [
'/ql/scripts/', # 标准路径
'/ql/data/scripts/', # 新版路径
'/ql/config/scripts/', # 配置路径
'./', # 当前目录
]
for base_path in possible_paths:
if os.path.exists(base_path):
return base_path
return './' # 默认当前目录
# 获取基础路径
BASE_PATH = get_ql_paths()
print(f"📁 检测到基础路径: {BASE_PATH}")
# 文件路径配置
DOWNLOAD_FOLDER = os.path.join(BASE_PATH, 'tg')
IP_FILE = os.path.join(BASE_PATH, 'tg/ip.txt')
HK_IP_FILE = os.path.join(BASE_PATH, 'tg/hkip.txt')
SG_IP_FILE = os.path.join(BASE_PATH, 'tg/sgip.txt')
# Session文件路径 - 尝试多个可能的位置
SESSION_PATHS = [
os.path.join(BASE_PATH, 'telegram_session'),
os.path.join(BASE_PATH, 'telegram_session.session'),
'/ql/scripts/telegram_session',
'/ql/data/scripts/telegram_session',
'/ql/scripts/telegram_session.session',
'/ql/data/scripts/telegram_session.session',
'./telegram_session',
'./telegram_session.session'
]
# 设置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[logging.StreamHandler(sys.stdout)]
)
logger = logging.getLogger(__name__)
def find_session_file():
"""查找session文件"""
for session_path in SESSION_PATHS:
if os.path.exists(session_path):
logger.info(f"✅ 找到session文件: {session_path}")
return session_path
# 如果没有找到,显示所有可能的路径
logger.error("❌ 未找到session文件,请检查以下可能的位置:")
for path in SESSION_PATHS:
logger.error(f" - {path}")
return None
def check_environment():
"""检查环境变量配置"""
missing_vars = []
if not API_ID:
missing_vars.append('TELEGRAM_API_ID')
if not API_HASH:
missing_vars.append('TELEGRAM_API_HASH')
if not PHONE_NUMBER:
missing_vars.append('TELEGRAM_PHONE')
if not CHANNEL_USERNAME:
missing_vars.append('TELEGRAM_CHANNEL')
if missing_vars:
logger.error(f"❌ 缺少环境变量: {', '.join(missing_vars)}")
return False
# 查找session文件
session_file = find_session_file()
if not session_file:
return False
logger.info("✅ 环境检查通过")
return True
class TelegramDownloader:
def __init__(self, api_id, api_hash, phone_number, channel_username):
self.session_file = find_session_file()
if not self.session_file:
raise ValueError("未找到session文件")
self.client = TelegramClient(self.session_file, api_id, api_hash)
self.phone_number = phone_number
self.channel_username = channel_username
logger.info(f"📁 使用session文件: {self.session_file}")
async def start(self):
"""启动客户端"""
try:
await self.client.start(phone=self.phone_number)
logger.info("✅ Telegram客户端启动成功")
return True
except Exception as e:
logger.error(f"❌ 启动失败: {e}")
return False
async def download_recent_csv_files(self, download_folder):
"""下载最近发布的CSV文件"""
try:
os.makedirs(download_folder, exist_ok=True)
logger.info(f"📡 正在连接频道: {self.channel_username}")
channel = await self.client.get_entity(self.channel_username)
logger.info(f"✅ 成功连接到频道: {channel.title}")
except Exception as e:
logger.error(f"❌ 连接频道失败: {e}")
return []
# 获取最近3天的文件
utc_now = datetime.now(timezone.utc)
three_days_ago = utc_now - timedelta(days=3)
logger.info(f"🔍 正在查找最近3天发布的CSV文件...")
downloaded_files = []
try:
async for message in self.client.iter_messages(channel, limit=200):
if message.media and hasattr(message.media, 'document'):
document = message.media.document
filename = None
for attr in document.attributes:
if hasattr(attr, 'file_name'):
filename = attr.file_name
break
if filename and filename.lower().endswith('.csv'):
message_date = message.date
if message_date >= three_days_ago:
logger.info(f"📄 找到CSV文件: {filename}")
file_path = os.path.join(download_folder, filename)
# 无论文件是否存在都重新下载,确保获取最新版本
try:
await self.client.download_media(message, file=file_path)
logger.info(f"✅ 下载成功: {filename}")
downloaded_files.append(file_path)
except Exception as e:
logger.error(f"❌ 下载失败 {filename}: {e}")
logger.info(f"📊 总共找到 {len(downloaded_files)} 个CSV文件")
return downloaded_files
except Exception as e:
logger.error(f"❌ 获取消息时出错: {e}")
return []
def find_region_preferred_files(self, csv_files):
"""查找优先处理的区域文件"""
hk_files = []
sg_files = []
other_files = []
for file_path in csv_files:
filename = os.path.basename(file_path)
if re.match(r'^IataHK\.csv-.*-IP\.csv$', filename):
hk_files.append(file_path)
logger.info(f"🇭🇰 找到HK优选文件: {filename}")
elif re.match(r'^IataSG\.csv-.*-IP\.csv$', filename):
sg_files.append(file_path)
logger.info(f"🇸🇬 找到SG优选文件: {filename}")
else:
other_files.append(file_path)
logger.info(f"📁 文件统计: HK={len(hk_files)}, SG={len(sg_files)}, 其他={len(other_files)}")
return hk_files, sg_files, other_files
def extract_443_ips_from_csv(self, csv_file_path):
"""从CSV文件中提取443端口IP"""
if not os.path.exists(csv_file_path):
return []
ip_addresses = set()
try:
with open(csv_file_path, 'r', encoding='utf-8', errors='ignore') as file:
sample = file.read(1024)
file.seek(0)
delimiter = ','
if ';' in sample and ',' not in sample:
delimiter = ';'
elif '\t' in sample:
delimiter = '\t'
reader = csv.reader(file, delimiter=delimiter)
headers = None
for row_num, row in enumerate(reader, 1):
if not row:
continue
if row_num == 1:
headers = [header.strip().lower() for header in row]
continue
# 查找端口列
port_column_index = None
for i, header in enumerate(headers):
if header in ['port', '端口', 'port_number', '端口号', 'dstport', 'portid']:
port_column_index = i
break
if port_column_index is None:
for i, header in enumerate(headers):
if 'port' in header:
port_column_index = i
break
# 检查是否为443端口
is_443_port = False
if port_column_index is not None and port_column_index < len(row):
port_value = str(row[port_column_index]).strip()
if port_value == '443':
is_443_port = True
if is_443_port:
# 查找IP列
ip_column_index = None
for i, header in enumerate(headers):
if header in ['ip', 'ip地址', 'ip_address', 'address', '地址', 'dstip', 'ipaddr']:
ip_column_index = i
break
if ip_column_index is None:
ip_column_index = 0
if ip_column_index < len(row):
ip_value = str(row[ip_column_index]).strip()
ip_match = re.search(r'\b(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b', ip_value)
if ip_match:
ip = ip_match.group()
if self.is_valid_ip(ip):
ip_addresses.add(ip)
logger.info(f"✅ 从 {os.path.basename(csv_file_path)} 提取到 {len(ip_addresses)} 个443端口IP")
except Exception as e:
logger.error(f"❌ 读取CSV文件时出错: {e}")
return list(ip_addresses)
def is_valid_ip(self, ip):
"""验证IP地址格式"""
try:
parts = ip.split('.')
if len(parts) != 4:
return False
return all(0 <= int(part) <= 255 for part in parts if part.isdigit())
except:
return False
def save_ips_to_file(self, ip_list, output_file):
"""保存IP地址到文件 - 始终覆盖输出"""
try:
# 确保输出目录存在
os.makedirs(os.path.dirname(output_file), exist_ok=True)
# 无论IP列表是否为空,都创建或覆盖文件
with open(output_file, 'w', encoding='utf-8') as f:
for ip in sorted(ip_list):
f.write(ip + '\n')
# 记录文件状态
if len(ip_list) > 0:
logger.info(f"💾 保存 {len(ip_list)} 个IP到 {output_file}")
else:
logger.info(f"📝 创建空文件 {output_file} (无IP数据)")
return True
except Exception as e:
logger.error(f"❌ 保存文件失败: {e}")
return False
async def close(self):
"""关闭客户端"""
await self.client.disconnect()
async def main():
# 检查环境
if not check_environment():
print("## 错误: 环境配置检查失败")
return
logger.info(f"🎯 目标频道: {CHANNEL_USERNAME}")
try:
# 初始化下载器
downloader = TelegramDownloader(API_ID, API_HASH, PHONE_NUMBER, CHANNEL_USERNAME)
# 启动客户端
logger.info("🚀 正在启动Telegram客户端...")
success = await downloader.start()
if not success:
logger.error("❌ 无法启动Telegram客户端")
return
# 下载CSV文件
csv_files = await downloader.download_recent_csv_files(DOWNLOAD_FOLDER)
# 无论是否找到CSV文件,都创建输出文件
all_ips = set()
hk_ips = set()
sg_ips = set()
if csv_files:
# 分离区域文件
hk_files, sg_files, other_files = downloader.find_region_preferred_files(csv_files)
# 提取所有443端口IP
for file_path in csv_files:
ips = downloader.extract_443_ips_from_csv(file_path)
all_ips.update(ips)
# 提取HK IP
for file_path in hk_files:
ips = downloader.extract_443_ips_from_csv(file_path)
hk_ips.update(ips)
# 提取SG IP
for file_path in sg_files:
ips = downloader.extract_443_ips_from_csv(file_path)
sg_ips.update(ips)
else:
logger.info("ℹ️ 未找到CSV文件,将创建空的输出文件")
# 始终保存文件(覆盖更新)
downloader.save_ips_to_file(list(all_ips), IP_FILE)
downloader.save_ips_to_file(list(hk_ips), HK_IP_FILE)
downloader.save_ips_to_file(list(sg_ips), SG_IP_FILE)
# 输出结果
print(f"\n## 任务执行完成")
print(f"## 提取结果汇总")
print(f"- 目标频道: {CHANNEL_USERNAME}")
print(f"- 处理文件数: {len(csv_files)}")
print(f"- 总443端口IP: {len(all_ips)} 个")
print(f"- HK区域443端口IP: {len(hk_ips)} 个")
print(f"- SG区域443端口IP: {len(sg_ips)} 个")
print(f"- 输出文件: {IP_FILE}, {HK_IP_FILE}, {SG_IP_FILE}")
except Exception as e:
logger.error(f"❌ 初始化失败: {e}")
finally:
try:
await downloader.close()
logger.info("👋 Telegram客户端已关闭")
except:
pass
if __name__ == "__main__":
asyncio.run(main())
print("======================================")
print("脚本执行完毕")
print("======================================")