
用青龙面板监控人行纪念币发行公告,并推送消息到手机
前言
前几天中国龙银币预约,发行价460元,市场价5000左右,这个大羊毛差点错过。今天闲着写了一个青龙脚本监控中国人民银行发行公告,当有新发行公告时推送消息到手机上。因为人行网站是禁止爬虫,则改为关键词匹配。下面把代码和方法分享出来。
运行效果演示:

配置方法:
- 1、进青龙面板,添加脚本pbc_history.py,然后手动运行生成pbc_history.txt,手动添加日志文件也行。

- 2、在环境变量中添加推送秘钥。也可以直接在上面的脚本代码中写死。

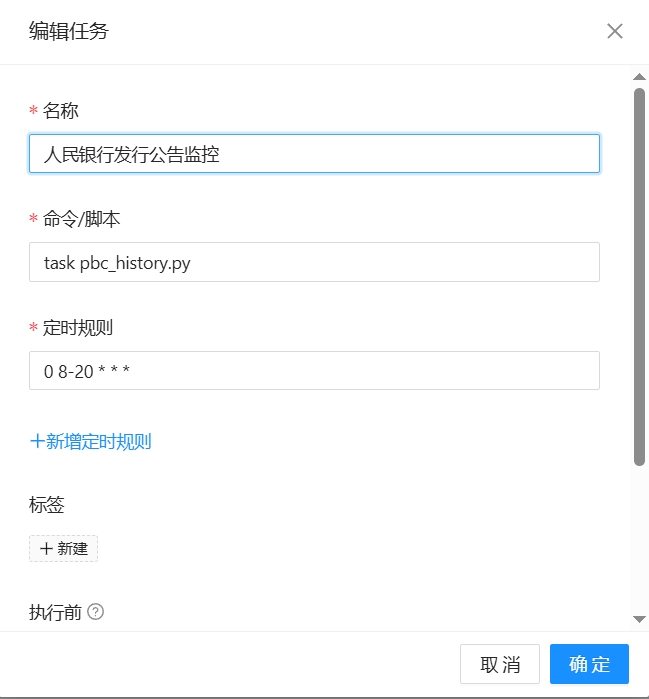
- 3、新添加一个任务,命令为:task pbc_history.py ,运行时间为0 8,20 * 表示每天8点和20点各执行一次。
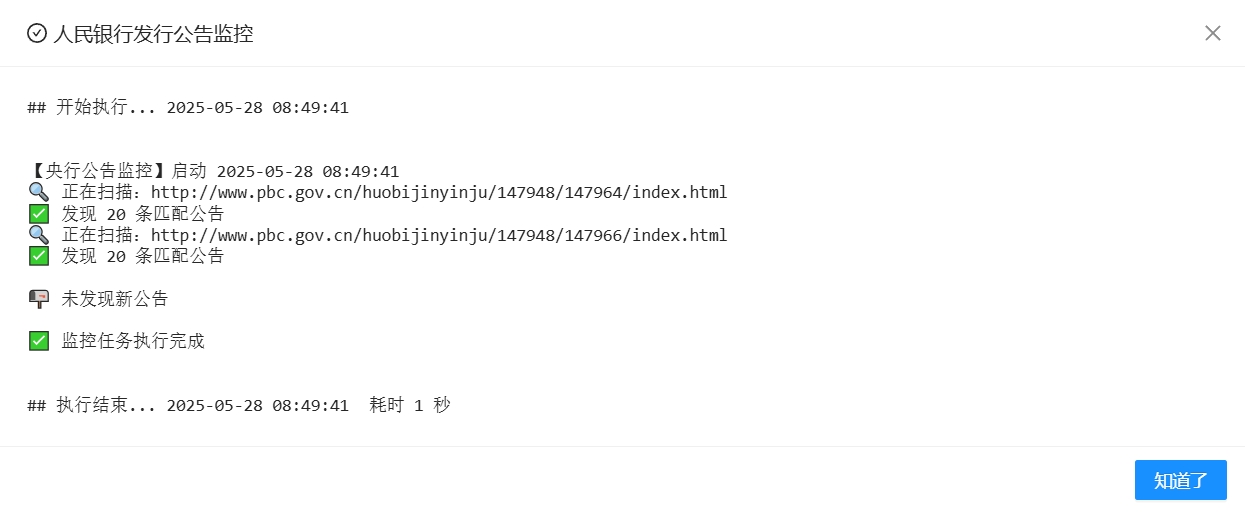
- 4、手动运行一次,匹配成功。
最后附上脚本代码:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import time
import re
import os
import hashlib
import requests
from datetime import datetime
from bs4 import BeautifulSoup
from urllib.parse import urljoin
# ========================
# 配置参数(环境变量读取)
# ========================
PUSHDEER_KEY = os.getenv('PUSHDEER_KEY'), # 环境变量中添加
PUSHDEER_API = os.environ.get("PUSHDEER_API", "https://api2.pushdeer.com/message/push")
HISTORY_FILE = os.path.join(os.path.dirname(__file__), "pbc_history.txt") # 存储在同级目录
ANNOUNCEMENT_PATTERN = re.compile(
r'中国人民银行.*公告|.*工作安排|关于.*公告|.*发行计划|中国人民银行.*发行计划'
)
# ========================
# 通用配置
# ========================
COMMON_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
TARGET_URLS = [
"http://www.pbc.gov.cn/huobijinyinju/147948/147964/index.html",
"http://www.pbc.gov.cn/huobijinyinju/147948/147966/index.html"
]
# ========================
# 核心功能函数
# ========================
def get_page_content(url):
"""获取目标网页内容"""
try:
response = requests.get(url, headers=COMMON_HEADERS)
response.encoding = 'utf-8'
response.raise_for_status()
return response.text
except requests.RequestException as e:
print(f"[ERROR] 请求异常: {e}")
return None
def parse_announcements(html, base_url):
"""解析公告列表(支持动态base_url)"""
soup = BeautifulSoup(html, 'html.parser')
announcements = []
for link in soup.find_all('a'):
title = link.get_text().strip()
if not ANNOUNCEMENT_PATTERN.search(title):
continue
href = link.get('href')
if not href:
continue
# 自动处理相对链接
absolute_url = urljoin(base_url, href)
announcements.append({'title': title, 'link': absolute_url})
return announcements
def get_first_sentence(url):
"""获取公告正文首句"""
try:
response = requests.get(url, headers=COMMON_HEADERS)
response.encoding = 'utf-8'
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
content_selectors = [
'div.article-content',
'div.content',
'div.article',
'td.content',
'div#content',
'div#zoom'
]
content = next(
(soup.select_one(sel) for sel in content_selectors if soup.select_one(sel)),
soup.body
)
if first_para := content.find('p'):
text = first_para.get_text().strip()
if sentences := [s.strip() for s in text.split('。') if s.strip()]:
return sentences[0] + '。'
return None
except Exception as e:
print(f"[ERROR] 获取内容异常: {e}")
return None
def send_push_notification(title, message):
"""发送推送通知"""
payload = {
"pushkey": PUSHDEER_KEY,
"text": title,
"desp": message,
"type": "markdown"
}
try:
response = requests.post(PUSHDEER_API, data=payload)
response.raise_for_status()
print("[INFO] 推送成功")
return True
except Exception as e:
print(f"[ERROR] 推送失败: {e}")
return False
# ========================
# 持久化操作(路径优化)
# ========================
def load_history():
try:
with open(HISTORY_FILE, 'r', encoding='utf-8') as f:
return {line.strip() for line in f}
except FileNotFoundError:
print(f"[INIT] 首次运行,创建历史记录文件:{HISTORY_FILE}")
return set()
def save_history(history):
with open(HISTORY_FILE, 'w', encoding='utf-8') as f:
f.write('\n'.join(history))
# ========================
# 主程序逻辑(日志优化)
# ========================
def main():
"""支持多页面监控的主程序"""
history = load_history()
new_items = []
print(f"\n【央行公告监控】启动 {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
for target_url in TARGET_URLS:
print(f"🔍 正在扫描:{target_url}")
if html := get_page_content(target_url):
announcements = parse_announcements(html, target_url)
print(f"✅ 发现 {len(announcements)} 条匹配公告")
for ann in announcements:
ann_id = hashlib.md5(f"{ann['title']}{ann['link']}".encode()).hexdigest()
if ann_id not in history:
new_items.append((ann, ann_id))
else:
print(f"⚠️ 内容获取失败:{target_url}")
if new_items:
print(f"\n🎉 发现 {len(new_items)} 条新公告")
for ann, ann_id in new_items:
content = get_first_sentence(ann['link']) or "点击查看详情"
message = f"**{ann['title']}**\n\n{content}\n\n[查看详情]({ann['link']})"
if send_push_notification("央行新公告", message):
history.add(ann_id)
time.sleep(1)
save_history(history)
else:
print("\n📭 未发现新公告")
print("\n✅ 监控任务执行完成\n")
if __name__ == "__main__":
main()